Jose Storopoli, PhD
Zero-cost Abstractions
In programming language circles there’s a recently trend of discussing a concept called zero-cost abstractions: the ability to use higher-levels abstractions without suffering any loss of performance.
Zero-cost abstractions allows you to write performant code without having to give up a single drop of convenience and expressiveness:
You want for-loops? You can have it. Generics? Yeah, why not? Data structures? Sure, keep’em coming. Async operations? You bet ya! Multi-threading? Hell yes!
To put more formally, I like this definition from StackOverflow:
Zero Cost Abstractions means adding higher-level programming concepts, like generics, collections and so on do not come with a run-time cost, only compile time cost (the code will be slower to compile). Any operation on zero-cost abstractions is as fast as you would write out matching functionality by hand using lower-level programming concepts like for loops, counters, ifs and using raw pointers.
Here’s an analogy:
Imagine that you are going to buy a car. The sales person offers you a fancy car praising how easy it is to drive it, that you don’t need to think about RPM, clutch and stick shift, parking maneuver, fuel type, and other shenanigans. You just turn it on and drive. However, once you take a look at the car’s data sheet, you are horrified. The car is bad in every aspect except easy of use. It has dreadful fuel consumption, atrocious safety ratings, disastrous handling, and so on…
Believe me, you wouldn’t want to own that car.
Metaphors aside, that’s exactly what professional developers and whole teams choose to use every day: unacceptable inferior tools. Tools that, not only don’t have zero-cost abstractions, rather don’t allow you to even have non-zero-cost anything!
Let’s do some Python bashing in the meantime. I know that’s easy to bash Python, but that’s not the point. If Python wasn’t used so widely in production, I would definitely leave it alone. Don’t get me wrong, Python is the second-best language for everything.
The curious case of the Python boolean

I wish this meme was a joke, but it isn’t. A boolean is one of the simplest data type taking only two possible values: true or false. Just grab your nearest Python REPL:
>>> from sys import getsizeof
>>> getsizeof(True)
28
The function sys.getsizeof returns the size of an object in bytes. How the hell Python needs 28 bytes to represent something that needs at most 1 byte? Imagine incurring a 28x penalty in memory size requirements for every boolean that you use. Now multiply this by every operation that your code is going to run in production over time. Again: unacceptable.
That’s because all objects in Python, in the sense that everything that you can instantiate, i.e. everything that you can put on the left hand-side of the = assignment, is a PyObject:
All Python objects ultimately share a small number of fields at the beginning of the object’s representation in memory. These are represented by the
PyObjectandPyVarObjecttypes.
Python is dynamically-typed, which means that you don’t have primitives like 8-, 16-, 32-bit (un)signed integers and so on. Everything is a huge mess allocated in the heap that must carry not only its value, but also information about its type.
Most important, everything that is fast in Python is not Python-based. Take a look at the image below, I grabbed some popular Python libraries from GitHub, namely NumPy (linear algebra package) and PyToch (deep learning package), and checked the language codebase percentage.

Surprise, they are not Python libraries. They are C/C++ codebases. Even if Python is the main language used in these codebases, I still think that this is not the case due to the nature of the Python code: all docstrings are written in Python. If you have a very fast C function in your codebase that takes 50 lines of code, followed by a Python wrapper function that calls it using 10 lines of code, but with a docstring that is 50 lines of code; you have a “Python”-majority codebase.
In a sense the most efficient Python programmer is a C/C++ programmer…
Here’s Julia, which is also dynamically-typed:
julia> Base.summarysize(true)
1
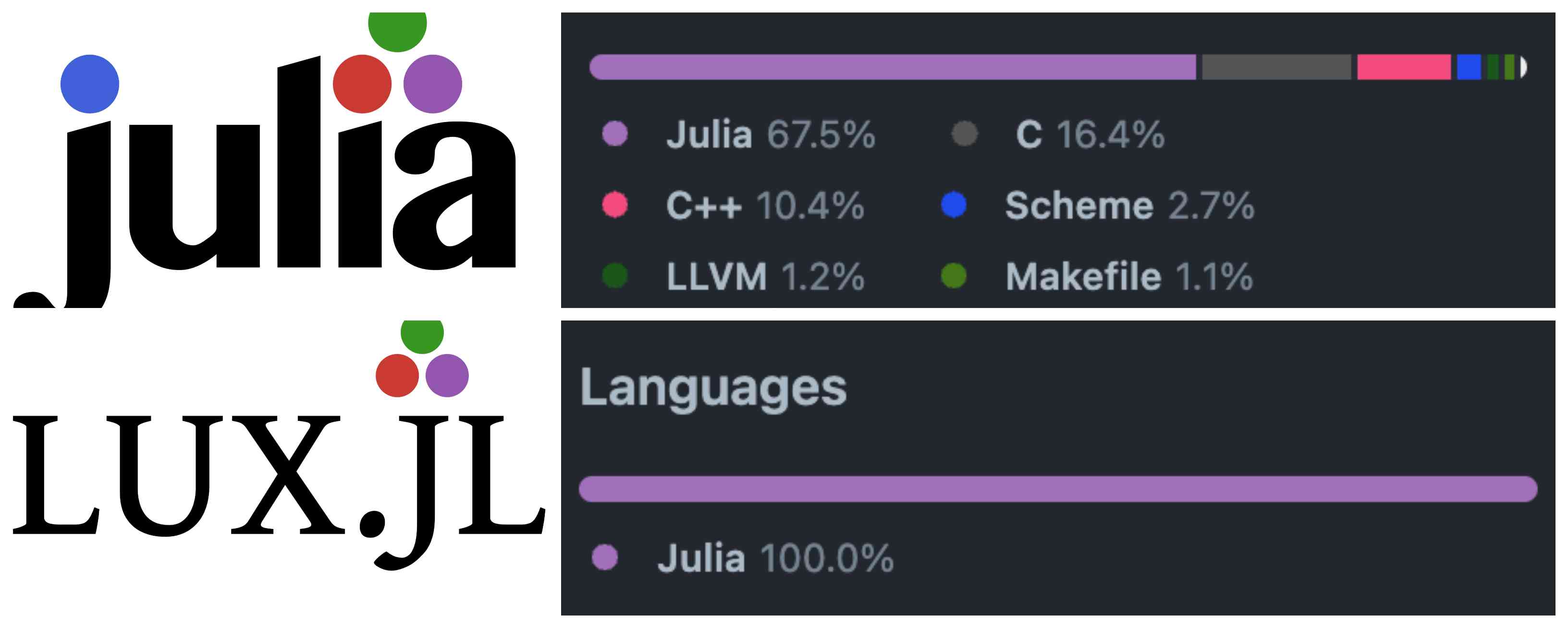
And to your surprise, Julia is coded in …. Julia! Check the image below for the language codebase percentage of Julia and Lux.jl (deep learning package).
Finally, here’s Rust, which is not dynamically-, but static-typed:
// main.rs
use std::mem;
fn main() {
println!("Size of bool: {} byte", mem::size_of::<bool>());
}
$ cargo run --release
Compiling size_of_bool v0.1.0
Finished release [optimized] target(s) in 0.00s
Running `target/release/size_of_bool`
Size of bool: 1 byte
More zero-costs abstractions
Let’s cover two more zero-costs abstractions, both in Julia and in Rust: for-loops and enums.
For-loops
A friend and a Julia-advocate once told me that Julia’s master plan is to secretly “make everyone aware about compilers”. The compiler is a program that translate source code from a high-level programming language to a low-level programming language (e.g. assembly language, object code, or machine code) to create an executable program.
Python uses CPython as the compiler. If you search around on why CPython/Python is so slow and inefficient, you’ll find that the culprits are:
- Python is dynamic-typed language.
- Python’s Global Interpreter Lock (GIL) restricts multi-threading capabilities.
- Python is interpreted, which means that Python code is executed sequentially: line-by-line.
- Python is garbage-collected: all memory its tracked, and allocated or deallocated which introduces overhead.
I completely disagree with almost all the above reasons, except the GIL. Python is slow because of its design decisions, more specifically the way CPython works under the hood. It is not built for performance in mind. Actually, the main objective of Python was to be a “language that would be easy to read, write, and maintain”. I salute that: Python has remained true to its main objective.
Now let’s switch to Julia:
- Julia is dynamic-typed language.
- Julia is interpreted, which means that Julia code is executed sequentially: line-by-line.
- Julia is garbage-collected: all memory its tracked, and allocated or deallocated which introduces overhead.
I’ve copy-pasted all Python’s arguments for inefficiency, except the GIL. And, contrary to Python, Julia is fast! Sometimes even faster than C. Actually, that was the goal all along since Julia’s inception. If you check the notorious Julia announcement blog post from 2012:
We want a language that’s open source, with a liberal license. We want the speed of C with the dynamism of Ruby. We want a language that’s homoiconic, with true macros like Lisp, but with obvious, familiar mathematical notation like Matlab. We want something as usable for general programming as Python, as easy for statistics as R, as natural for string processing as Perl, as powerful for linear algebra as Matlab, as good at gluing programs together as the shell. Something that is dirt simple to learn, yet keeps the most serious hackers happy. We want it interactive and we want it compiled.
(Did we mention it should be as fast as C?)
It mentions “speed” twice. Not only that, but also specifically says that it should match C’s speed.
Julia is fast because of its design decisions. One of the major reasons why Julia is fast is because of the choice of compiler that it uses: LLVM.
LLVM originally stood for low level virtual machine. Despite its name, LLVM has little to do with traditional virtual machines. LLVM can take intermediate representation (IR) code and compile it into machine-dependent instructions. It has support and sponsorship from a lot of big-tech corporations, such as Apple, Google, IBM, Meta, Arm, Intel, AMD, Nvidia, and so on. It is a pretty fast compiler that can do wonders in optimizing IR code to a plethora of computer architectures.
In a sense, Julia is a front-end for LLVM. It turns your easy-to-read and easy-to-write Julia code into LLVM IR code. Take this for-loop example inside a function:
function sum_10()
acc = 0
for i in 1:10
acc += i
end
return acc
end
Let’s check what Julia generates as LLVM IR code for this function. We can do that with the @code_llvm macro.
julia> @code_llvm debuginfo=:none sum_10()
define i64 @julia_sum_10_172() #0 {
top:
ret i64 55
}
You can’t easily fool the compiler. Julia understands that the answer is 55, and the LLVM IR generated code is pretty much just “return 55 as a 64-bit integer”.
Let’s also check the machine-dependent instructions with the @code_native macro. I am using an Apple Silicon machine, so these instructions might differ from yours:
julia> @code_native debuginfo=:none sum_10()
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 14, 0
.globl _julia_sum_10_214 ; -- Begin function julia_sum_10_214
.p2align 2
_julia_sum_10_214: ; @julia_sum_10_214
.cfi_startproc
; %bb.0: ; %top
mov w0, #55
ret
.cfi_endproc
; -- End function
.subsections_via_symbols
The only important instruction for our argument here is the mov w0, #55. This means “move the value 55 into the w0 register”, where w0 is one of registers available in ARM-based architectures (which Apple Silicon chips are).
This is a zero-cost abstraction! I don’t need to give up for-loops, because they might be slow and inefficient; like some Python users suggest newcomers. I can have the full convenience and expressiveness of for-loops without paying performance costs. Pretty much the definition of a zero-cost abstraction from above.
Using LLVM as a compiler backend is not something unique to Julia. Rust also uses LLVM under the hood. Take for example this simple Rust code:
// main.rs
pub fn sum_10() -> i32 {
let mut acc = 0;
for i in 1..=10 {
acc += i
}
acc
}
fn main() {
println!("sum_10: {}", sum_10());
}
We can inspect both LLVM IR code and machine instructions with the cargo-show-asm crate:
$ cargo asm --llvm "sum_10::main" | grep 55
Finished release [optimized] target(s) in 0.00s
store i32 55, ptr %_9, align 4
$ cargo asm "sum_10::main" | grep 55
Finished release [optimized] target(s) in 0.00s
mov w8, #55
No coincidence that the LLVM IR code is very similar, with the difference that integers, by default, in Julia are 64 bits and in Rust 32 bits. However, the machine code is identical: “move the value 55 into a w something register”.
Enums
Another zero-cost abstraction, in Julia and Rust, is enums.
In Julia all enums, by default have a BaseType of Int32: a signed 32-bit integer. However, we can override this with type annotations:
julia> @enum Thing::Bool One Two
julia> Base.summarysize(Thing(false))
1
Here we have an enum Thing with two variants: One and Two. Since we can safely represent all the possible variant space of Thing with a boolean type, we override the BaseType of Thing to be the Bool type. Unsurprised, any object of Thing occupies 1 byte in memory.
We can achieve the same with Rust:
// main.rs
use std::mem;
#[allow(dead_code)]
enum Thing {
One,
Two,
}
fn main() {
println!("Size of Thing: {} byte", mem::size_of::<Thing>());
}
$ cargo run --release
Compiling enum_size v0.1.0
Finished release [optimized] target(s) in 0.09s
Running `target/release/enum_size`
Size of Thing: 1 byte
However, contrary to Julia, Rust compiler automatically detects the enum’s variant space size and adjust accordingly. So, no need of overrides.
Conclusion
Zero-cost abstractions are a joy to have in a programming language. It enables you, as a programmer, to just focus on what’s important: write expressive code that is easy to read, maintain, debug, and build upon.
It is no wonder that zero-cost abstractions is a pervasive feature of two of my top-favorite languages: Julia and Rust.